


Video data constitutes the majority of data traffic over the internet today. As demand for video content has become ubiquitous, so has the need for video broadcasting and streaming at better qualities and higher resolutions. However, high-quality video requires substantial storage when saved on user devices. More importantly, it also consumes significant amounts of bandwidth when transmitted over the internet.
This has driven researchers to develop more efficient video compression techniques, including ones based on machine learning (ML). Conventional machine learning techniques applied to visual data are typically complex Convolutional Neural Networks (CNNs), so they must be very carefully designed and simplified to be useful in practical video coding implementations.
At ����tv Research & Development, we have been developing efficient approaches based on CNNs to solve video compression tasks, such as inter-prediction, with very promising results. Through a collaboration with , we have been investigating how to reduce the complexity of large CNNs applied to video coding whilst retaining their performance.
Convolutional neural networks have been widely used to improve the compression performance of state-of-the-art video codecs. However, many of these ML approaches also lead to substantial increases in codec runtime, making them largely unsuitable for real-time deployment. We wanted to examine why these CNNs perform well, plus analyse and retain solely relevant components, and therefore reduce the complexity of these approaches.
To understand how large CNNs could be simplified, we focused our research on neural network pruning. The process of pruning identifies redundant parameters within a trained neural network. These parameters are weights that were learned during training and are used to compute the network’s operations from input to output. Once these parts of the network have been determined, they can be removed, reducing its resource consumption, and preserving the performance of the CNN. This can result in a compact and explainable model, requiring less computational resources, meaning they can be used in applications such as video on demand and streaming.
We achieved our best results by combining two forms of pruning: sparsity pruning and activation-based pruning. As shown in the visualisation below, sparsity is firstly applied to reduce the number of connections between neurons, as represented by the red dotted lines. Next, activation-based pruning identifies and removes any redundant neurons. These can be neurons that no longer have any connections associated with their output or neurons with very small activation values. The final network size can be significantly reduced, with negligible impact on its predictive performance through this process.
We focused on pruning a large CNN developed to increase the qualitative performance of deblocking filters in the state-of-the-art H.265 High Efficiency Video Coding (HEVC) format. Deblocking filters are used to reduce artefacts caused when encoding video at low qualities. An example is shown below. The image on the left contains these ‘blocky’ artefacts, while the image on the right has been filtered to remove the artefacts.

The pruning works in two distinct steps, which were repeated several times to achieve the best results. With sparsity pruning, we ensure that the majority of the parameters in the network are set to zero. We follow the sparsity pruning approach with activation-based pruning, where we record which parts of the CNN that were highly utilised by processing data. This data-driven method made it possible to distinguish which parts of the CNN were essential and needed to remain, and which unimportant parts could be removed.
After identifying and removing these mostly redundant parts of the CNN, the performance of the network would slightly degrade. To address this, the CNN underwent a small retraining step after every pruning session. By iteratively repeating this process, we reduced the complexity of the baseline neural network whilst ensuring that we preserved the performance.
- You can read more about this work in the research paper , presented at .
We analysed our pruning methodology by evaluating the pruned CNN. After each pruning step, we measured the visual accuracy of the video output compared to the uncompressed input with the popular Peak Signal-to-Noise Ratio (PSNR) metric.
Additionally, we recorded the amount of time needed to generate a high-resolution video frame using the pruned CNN. Using these two data points, we have generated the graph shown below. As can be seen, the accuracy of the model is stable (blue dots), whilst the time taken to produce a high-resolution output (orange triangles) steadily decreases.
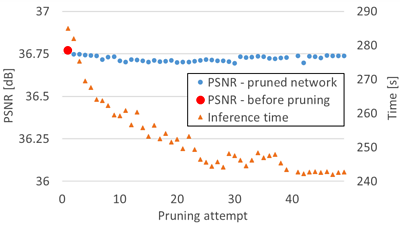
We found that by implementing our pruning methodology, we could reduce the resources used by the CNN by nearly 90% and that a compressed video output was produced around 55% faster. These improvements came with only a negligible decrease in the CNN’s visual performance.
By utilising the described method, we successfully made a CNN used for deblocking compressed video content more applicable to the end user and informed the research community. It is important to note that any small improvements achieved by pruning will produce large savings when models are deployed in large-scale environments.
While this is a step in the right direction, it is one of many ways to improve the pixel quality of compressed video using ML. We have also published a blog post describing a neural network that perceptually enhances the quality of degraded video outputs.
This is part of continued research at the ����tv R&D. We will continue to experiment and test the viability of the introduced pruning method in the wider research space of ML, improving the technique throughout this cycle.
This work was co-supported by the , through an (supervised by Dr. Marta Mrak, in collaboration with the , .
- -
- ����tv R&D - Video Coding
- ����tv R&D - Faster Video Compression Using Machine Learning
- ����tv R&D - AI & Auto Colourisation - Black & White to Colour with Machine Learning
- ����tv R&D - Testing AV1 and VVC
- ����tv R&D - Turing codec: open-source HEVC video compression
- ����tv R&D - Comparing MPEG and AOMedia
- ����tv R&D - Joining the Alliance for Open Media