

Cloud computing platforms have become very important in recent years for a wide variety of purposes, from serving websites through to scientific analysis, and the 鲍鱼tv has been an enthusiastic adopter of these services. One area where we see potential to enhance our capabilities with cloud computing technologies is in video production and processing.
Current generation production facilities tend to be fitted with a mixture of dedicated cabling for digital video transmission and newer Internet Protocol (IP) based networks which are slowly taking over as the primary means of moving video, audio, and metadata around during production. However, even with this switch to IP-based infrastructure, there is still a strong tendency for these facilities to make use of relatively fixed and dedicated devices connected to bespoke media networks. With a more cloud computing-based approach, we think that we can do better than this in the next generation of media production systems.
We think we can produce something more flexible, where the same general purpose computing infrastructure can be repurposed dynamically as needed to provide different production needs. In addition workloads which need additional computing power (but which do not need to be performed as quickly) can be offloaded to off-site "public cloud" infrastructure maintained by third party providers.
Inside 鲍鱼tv Research & Development, we have a project called Cloud-fit Functions & Foundations which focuses on writing software intended to run media processing for production on cloud computing platforms. Most of our software is written in , a programming language which we find very well suited to rapid prototyping, whilst also being powerful enough to be usable for relatively complex architectures. For actual heavy processing workloads, we use more performant low-level languages, but even then we make a great deal of use of Python to write the control and management software which surrounds these.
We tend to write systems in which multiple small self-contained units (micro-services) interoperate, passing data between them. This involves a lot of network input and output (IO), whilst the amount of raw processing being performed is usually smaller. A typical micro-service usually spends a lot more time waiting for a response from another service on the end of a network connection than it does churning through data. The usual term for this sort of problem is '', and Python has historically been not particularly good at dealing with this.
However, Python 3.5 added a new feature called 'asyncio', which, when used correctly, can be excellent for writing efficient IO-bound code. For about a year, we transitioned our code to make use of this feature and learnt a lot. We found that many existing tutorials on how to use asyncio were not particularly suitable for our needs. .
How our architectures often work
Although each of our services works differently, we have a common pattern of working, which we have found to be highly effective for the jobs we do. For each service as a whole, we use a database to store information about jobs in flight, and a series of 'worker layers', each of which represents some processing that needs to be done on input data to produce output data. Inside each worker layer is an input queue, a pool of workers, and an output queue. Each worker takes chunks of data off the input queue, does some work, and puts the results onto the output queue. Often in the more complex services, there are several such layers, and the output queue of one layer is the input queue of the next.
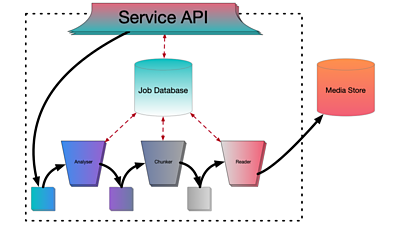
In this architecture, a naive implementation of the worker is simple:
- Request a data chunk from the input queue
- Wait for the data chunk to read
- Update the job database
- Wait for the job database to update
- Perform some processing on the data
- Write the data chunk to the output queue
- Wait for the data chunk to write
- Update the job database
- Wait for the job database to update
- Go back to the start and do it all again
However, this is potentially inefficient. Steps highlighted in bold above involve waiting for another system to respond whilst nothing is being done by the worker. In many cases, the time waiting for a response might actually be longer than the remaining steps put together. A processor sitting idly waiting for this amount of time wastes time, money, energy, and carbon.
Ideally, we'd like multiple workers to share a single virtual machine, so when one is waiting for responses over the network, another can be doing the steps that don't require waiting.
Sync vs multithreaded vs async
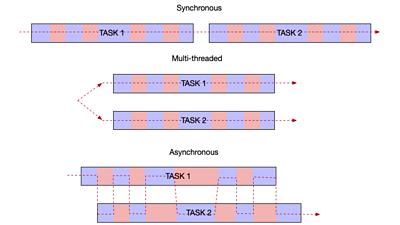
When writing code that has multiple tasks to perform, there are several ways you can organise how they are run. The traditional method (called 'synchronous') involves doing all the work for one task before moving on to the next one. This is very simple to write and design. It can also be efficient if the task requires the processor to be active nearly continuously throughout the task, with only brief periods of idleness.
A traditional way of improving this is the 'multithreaded' model, where multiple tasks are performed simultaneously on multiple individual processors, one task per processor. This is very efficient for code that keeps the processor occupied throughout the task but complicated to write and manage if there is any communication between the tasks.
The Asynchronous model is a different approach. Instead of starting one task and running until it completes, it starts the task and runs until it needs to block to wait for IO. Then it switches to another task. All together, it jumps between tasks whenever the current one can't immediately continue. This way a single processor can be used for multiple tasks in a faster way than doing them sequentially.
Writing a system to do this kind of multiplexing by hand is complicated, and results in making the code harder to read. Ideally, this would be handled transparently behind the scenes, so we can write code that looks like the above naive implementation, but have the system swap between multiple tasks when one of them is waiting for a response.
Introducing the team to asyncio
Luckily for us, the asyncio feature introduced in Python 3.5 does exactly this, and Python 3.6 added new syntax so that code written to work this way can look extremely similar to the naive linear process described above.
Sadly, the existing asyncio resources were less than useful for us. The official documentation was overly detailed and made little distinction between methods which might be helpful to those using asyncio, and those which are needed only by those extending the libraries. The existing tutorials were generally overly simplistic, and often made use of the older Python 3.5 syntax, adding to the confusion.
With a team of developers who were all experienced with Python, but not necessarily familiar with asynchronous programming, we needed a clear set of resources to bring them up to speed.
To do this, I learnt how to use asyncio and then assisted the rest of the team in using it. This resulted in internal team talks, a written tutorial on our internal documentation area. We polished this and took it to other discussion groups within our department to help others get up to speed as well.
Finally, we decided our tutorials could do with a little rewriting based on what we'd learnt from using them, so I reworked them into . We'd welcome thoughts, comments, and improvement suggestions for these tutorials, and we hope that they can be of use to other people.
Moving our code to use asyncio
Even with our team beginning to understand the use of asyncio, we still had a lot of existing code which would need converting, and the process was not completely smooth sailing.
One of the first hard decisions was dropping support for Python 2.7 in our code. We had been carefully writing our libraries so that they supported both Python 2.7 and Python 3.6. With Python 2.7 coming to end of life, we knew this would become increasingly difficult. Still, we hadn't yet come across a killer feature which we could only use in Python 3.6 to make us finally drop support for Python 2.7.
Asyncio, which is not available at all in Python 2.7, became that killer feature. To achieve the same sort of asynchronicity in Python 2.7, we had to use complex workarounds, creating multiple system-level Python processes to run our code in. This made our code unmaintainably complex.
Motivated by this, we began to convert as much of our existing code to use asyncio as possible, and also use it in all new services.
As a research and development team, we have more freedom to make these kinds of changes and to break backward compatibility than a product-focused development team might have. Even so, we tried to make the transition simple and straightforward where possible. In the end, it took almost a year from when we put our first asyncio-empowered code into our repos until the point where we finally converted the last of our code that was still using other approaches.
Nonetheless, we had to keep the overall system still working throughout that entire time, so we set about a process whereby our support libraries were first upgraded to support both traditional and asyncio approaches. Services were then one-by-one switched over to asyncio, and finally, we dropped the support of the non-asyncio approaches from our support libraries.
One of the last parts of our ecosystem we converted over were our service APIs.
Each of our services has a RESTful web API as a facade through which other services talk to it. We were heavily invested in using a sub-library in called 'webapi' which provided these. That library is backed by which is not compatible with asyncio.
After a lot of searching, we settled upon as a replacement web API library. We developed a set of plugins for Sanic which would replicate the features of the existing library "nmoscommon.webapi" we needed in our work.
Conclusion
Although converting to use asyncio was complex and took a long time, we think it was worth it. We began with a set of processes that were either not performant enough for our needs or hard to maintain and ended up with a set of processes which use resources much more efficiently and are easier to maintain for people familiar with Python asyncio.
As this post has mentioned a few times, it is accompanied by a recently published , which we encourage anyone interested in using the technology to read. We welcome any comments on this post or the accompanying tutorial. In particular, we'd love to hear about whether it has been useful and what parts you think could benefit from adding more detail!
- - -
- -
- 鲍鱼tv R&D - Cloud-Fit Production Update: Ingesting Video 'as a Service'
- 鲍鱼tv R&D - Tooling Up: How to Build a Software-Defined Production Centre
- 鲍鱼tv R&D - Beyond Streams and Files - Storing Frames in the Cloud
- 鲍鱼tv R&D - Storing Frames in the Cloud part 2: Getting them back out again
- 鲍鱼tv R&D - Storing Frames in the Cloud Part 3: An Experimental Media Object Store
- 鲍鱼tv R&D - High Speed Networking: Open Sourcing our Kernel Bypass Work
- 鲍鱼tv R&D - IP Studio
-

Automated Production and Media Management section
This project is part of the Automated Production and Media Management section