
Since it's my turn to write weeknotes, I'm focusing on a topic that I've been involved with over the last few years - how we measure the accuracy of speech to text systems
How we measure speech to text systems
We have been working on a based speech to text system for a number of years. This software has been used extensively across the organisation from everything to aiding in , to monitoring and helping teams navigate of long form content.
We measure the accuracy of our system with each release to confirm that our predictive models are improving over time. Additionally we keep track of the performance of commercial providers so we can benchmark ourselves against the quality of available alternatives.
The speech to text field has been gaining momentum over the past few years as more and more services become available and open source implementations have begun to lower the barrier to entry to building your own system. In the next few paragraphs I aim to give some insights into how we measure system outputs in the hope it may be useful to others purchasing or building a speech to text service.
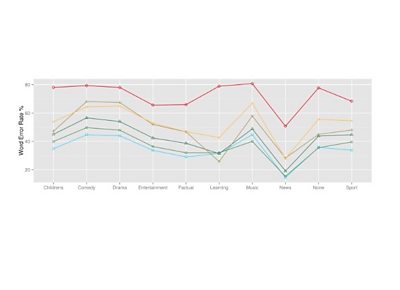
Measuring Word Error Rate
The main metric in measuring a system's accuracy is the Word Error Rate. At its simplest this is a measure of similarity derived from the Levenshtein distance of a reference transcription - as in the ground truth human-annotated version of the spoken word - against the hypothesis, the automated output of a speech to text system.
The word error rate is computed as the number of substitutions, deletions and insertions in the hypothesis over the total number of words in the reference. As such it provides not only a single figure to measure accuracy against but also insight into how many words a system got wrong, missed entirely or pulled out of thin air!
While using the Levenshtein distance on the entirety of the reference and hypothesised transcript produces a valid measure of word error rate it does not take into account any timing information. This may or may not be significant depending on your use case, for example the speech recognition for voice UI based devices such as Alexa may not require word level timing information. The ����tv use cases for our Kaldi system almost always involve long form content though, where accurate word level timing is crucial and must be factored into the Word Error Rate calculation.
In order to measure the word error rate whilst considering timing information we use the . This software is widely used throughout academia to measure speech to text systems on standard datasets. Although slightly archaic SCTK is a very powerful piece of software, it first aligns the reference and hypothesis transcripts by time and then performs a dynamic programming algorithm similar to the Levenstein distance to measure the word error rate. In-depth statistics are provided that allow us to see where the system went wrong and categorise errors by speaker or content type.
Test Data
Once we have an understanding of the metrics and tools involved in measuring system accuracy we need some reference material to test against. There are many datasets available for this task, some notable ones include the (very clean speech sentences read from WSJ), TED-LIUM (based on TED talks), LibriSpeech (based on audio books from LibreVox project) and (a crowd sourced dataset from Mozilla).
Using one of the above datasets is a good choice to start testing your own system or commercial outputs, and as the datasets are used extensively in academia, doing so allows you to compare against the published state-of-the-art.
However, there is no substitute for testing using the type of material you actually intend to run the system on. In our case this is a cross section of British TV and Radio output, and some of this content is quite far from the above datasets - imagine the difference between the audio from a TED talk and that from football commentary or the dialogue in a fast paced drama.
It is important that our measurements reflect our real world use cases and as such we created our own test datasets based on ����tv output. We were lucky to be participating in the with a number of academic partners who helped us create a testing dataset of over 60 ����tv TV programmes. Using this initial dataset and the guidance from our partners we have been able to create further datasets to test the system against.
Creating reference material is a long and expensive process - it essentially requires a very accurate human transcription segmented into speaker turns with timing information. Additionally a common set or rules around annotating hesitations, numbers and dates, etc must be considered.
Not all organisations benefit from the academic help we had, but for anybody investing significant time or money in speech recognition technologies it is still desirable to look into creating some of your own test data. Even a small amount of reference material based on your specific use case will be invaluable as a supplement to the more prevalent public datasets.
By creating our own test dataset we are able to set more realistic expectations around the technology. As an example, published results on the Wall Street Journal dataset show almost perfect accuracy with less than 3% error - this may imply that speech recognition is largely a solved problem. However, we have found that most systems tested using our datasets have more than a 30% error rate for a lot of content genres such as comedy or drama. This excludes the technology from many ����tv use cases such as completely automated subtitle creation.
Additionally by using our own datasets to test commercial providers we can hold their claims of accuracy to account based on our use cases, allowing us to more intelligently balance their features vs pricing.
Hopefully this brief insight into the tools and data we use to measure speech to text systems is of use to some people, you can read a more in-depth overview of the work we have done in this area in our recently published article in the SMPTE Motion Imaging Journal and find out more at our speech to text project page
And now over to the rest of the team for our weekly updates …
����tv Four
Tim, David and Jakub have entered the final stages of work on the ����tv Four machine learning project, processing many more programmes than before and generating some output with this larger dataset, as well as finessing screen designs.
Kristine worked on cleaning up the code for her audio player prototype and started looking into React.
Chris Newell has added a “mentions” tagging function to our Starfruit tagging system. Starfruit already provides “about” tags which describe what news and sport articles are primarily about. The new function identifies all the entities and themes mentioned in an article.
Better Radio Experiences
Libby improved some of the documentation for Better Radio experiences, while starting an RFID podcast player based on Radiodan - the goal is to help an artist at Pervasive Media Studio with her work in this area.
Autonomous Cars Content Experiences
Joanne and Joanna interviewed 26 people over 3 days for the autonomous cars project. They used a guerrilla approach, aiming at getting feedback on the stories developed during the first workshop and to get more insights into behaviour and consumption patterns in cars. Lots of audio feedback was generated. Joanna is starting the high level analysis by quote extractions from the transcripts. Barbara has been thinking about next steps for the project and look at feasible options.
Web Standards
Chris has been working on documenting use cases and requirements for timed events synchronised to A/V media in the browser, in particular requirements for subtitle caption display.
Chris and Lucas have been preparing for the next W3C Media & Entertainment Interest Group conference call, where we’ll be discussing HTTP/2 Server Push and multicast media delivery for scaleable live media distribution on the Web.
Chris and Alicia have restarted building prototypes to demonstrate the W3C Presentation API and Remote Playback API. We’re currently working on a prototype that uses the Presentation API to open a page that uses the ����tv Standard Media Player to play video. Related to this, Chris had a very useful conversation with Nigel E about the being considered for the Open Screen Protocol, which is the open standard set of protocols in development to support the W3C APIs.
Chris has also done a little more on preparing a lunchtime lecture to explain how the web standards process works.
Talking with Machines
Ant has been working on a demo to simulate voice calls in browser using the Web speech API and for natural language understanding.
Nicky and Henry have been working on the next voice experience from ����tv R&D. It’s a Radio 3 collaboration called The Unfortunates. They’ve been designing and implementing the user flow of the experience and doing some bug fixing, and have now added images with additional interaction points so it will work for voice devices with screens, reflecting the current trend of the platforms in moving towards multi-modality. They’ve also been examining the rights to ensure that can now be broadcast on Alexa.
The team have been reviewing the writers submissions for The Next Episode (the working title to our third voice experience) we have chosen a writer and hope to begin production in September. The plan is to make this a collaborative project whereby writers, UX designers, producers, developers and users all contribute to the production process.
Nicky and Henry ran a transfer review session with the ����tv Voice and TS&A teams to reflect on the tech transfer of the voice content management system called Orator. It was useful to appraise this process and look at how we can collaborate with the main ����tv voice department again in future. We then went out for some summer drinks to celebrate.
Henry has been working with the QMU students, including building a UI and organising user testing with Tim and Jo.
New News
Nieman Journalism Lab did a great , based on an interview with Tristan - and Tristan met and talked to a few people about our work off the back of this. We presented our work to the rest of R&D in a special lunchtime session.
Visual Journalism have built a pilot of one of our early prototypes, “Expander”. They’re just published the first story and are running a multi-variate test with it
We ran a user test with another underserved audience, women from 28-45 and we tested a series of prototypes that we’d developed for a younger Generation Z audience. We observed an anecdotal shift in the discovery of news content which closely mirrors the younger audiences. TV and radio is no longer the primary source of news but these have instead been replaced by social media or news brought to their attention by family and friends on private chat app groups. They also tend to skim and dig, and like the younger audiences, prefer text over video and audio - although not exclusively.
Our nested, granular Timeline prototype got a mixed reaction, our scrollable video prototype didn’t test well at all, but our Perspectives prototype showing all sides of a story worked really well again.
Tellybox
Alicia has been integrating Redux (React) in the 5-2-1 Tellybox prototypes, while Libby has been thinking about next steps, particularly evaluation.
-

Internet Research and Future Services section
The Internet Research and Future Services section is an interdisciplinary team of researchers, technologists, designers, and data scientists who carry out original research to solve problems for the ����tv. Our work focuses on the intersection of audience needs and public service values, with digital media and machine learning. We develop research insights, prototypes and systems using experimental approaches and emerging technologies.