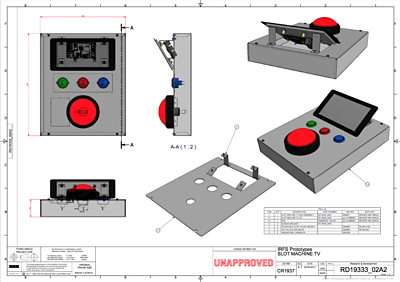

Since I'm writing weeknotes this week, I'm going to write in a little more depth about , the project I run about exploring the future of television experiences in the home.
The Tellybox team have a demo paper at , "", so we have taken our nine prototypes to Hilversum, somewhat regretting having nine of them, rather than, say, one. Tim, Kristian and I have spent a few days making sure they all work and putting two of them in the new cases that the CAD team designed for us (see Chris Jenkin's robust case design above). With Joanne's help, Tim and I have turned the "All Roads Lead to iPlayer" programmes clusters from a poster into an indexed atlas to make it more portable.
The point of attending TVX - not the unfortunately-similarly-named-adult TV channel but a conference about the user experience of TV - is twofold: to get further feedback on our prototypes from a completely different group of people, and to talk to this specific group about our approach - namely using design fictions and other partial experience prototypes to cheaply and quickly gather authentic feedback about which ways we ought to direct our efforts.
A really important aspect of the our work is this: to find out what we ought to make, we need to find out what we don't know we don't know - about people and what they may feel about future technologies. We've used several techniques to try and get to this, including user research and quantitative research, which contextualise the work and set us off in directions that are important to people. Creativity too, is vital, as we need to able to come up with new and unusual approaches to the problems people have - "".
Ultimately though, to understand how people might react to a technology, the approach that makes people want to talk to us and gives them a sense of what it might feel like to have a piece of technology in their home, is to present them with a physical representation of it that they can interact with. It doesn't have to be perfect (and in some cases it doesn't even have to be real). These prototypes are a point on a path to mapping out a kind of product space based on user needs, akin to .
Here are the rest of the team's notes:
Experiences
For , Tom and Ant have continued work on the editor and the engine for the Rosina project. They've created a Lambda service that checks that a single or group of audio files falls within the maximum duration of a response from the Alexa or Google ����tv. They have also reviewed the next version of the script and have commenced the third iteration of the experience.
Andrew and Joanne have started to test the two prototypes we made with ����tv Children’s, which explore new experiences for children using voice activated devices. The sessions take place in the home / family environment with children aged between 6 and 8. Similar sessions will be run by ����tv Children’s in Salford.
Barbara has been closely monitoring performance of the . We had a peak of over 79k pageviews on the day leading to the election with over 400 concurrent users. This shows how stable the build is that our team did. It's a really positive outcome and we are looking at possibly over 500k page visits in 1 month since launch.
Thomas, Tristan and David had a couple of short workshops on creating a project canvas for the #newnews project. In his ongoing landscape research Tristan talked to Alli from News Labs, Paul Bradshaw from Birmingham City University and Matt Locke from Storythings. Names withheld, but it was generally agreed that this was a fertile area of research:
"...assumptions about the 'right length' to write to may have no basis in how people read at all""...the biggest problem for media right now is how to restore context to news given the dominance of the the social platforms"
.
Discovery Team
David continued exploring themes around public service internet that could help shape future work or areas to investigate. Some nearer term thinking, based on transparent use of data and recommendations, included ideas like timelines, dashboards and personalised schedules, these can be considered individually or in combination. He also started thinking about the idea of digital well-being, what does it mean and how can it improve people’s use of digital services?
Tim has had a couple of days away doing Mental Health First Aid Training. He's started work on the prototype ����tv in Context browser extension, as well as continuing maintenance and support of the Freebird pipeline (and coaxing on the last few bits of the transfer process - the runbook review in particular).
Tim has also been planning the ‘Decentralization' space at MozFest, with Ian and Jon from our North Lab, where they've opened a
Chris Newell has completed the first part of our experimental Quote Identification and Attribution pipeline: a Cue Verb classifier, which identifies verbs (e.g. “say”) which indicate the presence of a direct or indirect quotation. A classifier trained on simple text features achieved surprisingly good performance (84% precision, 68% recall) which we should be able to improve by including more sophisticated features.
He has also been exploring additional sources of training data for our Starfruit tag suggestion system. The system previously relied solely on text features extracted from documents, but these documents often have additional metadata, such as location and author. Using this metadata during training was found to improve performance - but only when similar metadata is available for the documents to be tagged.
Data team
Ben has been benchmarking various ways of making the Kaldi speech to text system perform as a streaming system, where users need to wait much less time to begin getting results. He's found the best compromise between speed and reliability to be splitting the input stream into short 1 minute segments, processing these as individual segments.
Matt and Chrissy have been continuing to improve the Tensorflow Speech to Text project. Chrissy is creating a new model using a corpus of TED talks which is common in academic benchmarks. Matt has been integrating the output of our Tensorflow neural network with WFST graphs built in the Kaldi system, following the approach .
Ben has integrated Vault into our Nomad cluster the is used to power the project. securely stores all our sensitive information for configuring various services.
Denise has written up a Technote on how to 'Fuse' various machine learning algorithms to perform person identification and tracking in video. This includes transcriptions, speaker ID, face recognition and clothing detection.
Other stuff
We've all moved into our new home in Centre House from OnEustonSquare. Sarah organised a tour of the building for us, to meet colleagues in each of the teams based here.
Libby has been gathering lists of R&D radio and audio people to talk to as part of the High Quality Radio experiences project.
Barbara worked in the past sprint to formalise her thinking around the role of ����tv content in self-driving cars and wrote a project proposal for its next step: she's starting to dig into who is doing what in the rest of the organisation in this field.
-

Internet Research and Future Services section
The Internet Research and Future Services section is an interdisciplinary team of researchers, technologists, designers, and data scientists who carry out original research to solve problems for the ����tv. Our work focuses on the intersection of audience needs and public service values, with digital media and machine learning. We develop research insights, prototypes and systems using experimental approaches and emerging technologies.